说明:在安装zookeeper+Hbase之前,我们应该已经将hadoop集群搭建好了(三个节点),并且验证启动成功。因为HBase是一种构建在HDFS之上的分布式、面向列的存储系*统。
zookeeper安装及配置
- 貌似hBase自带的zookeeper只能用作伪分布式,想用于完全分布式要下载外部的zookeeper自行安装,因为我用的hadoop版本为2.2.0,根据官网提供的版本信息对照表选择安装3.4.5版本的zookeeper。
- 利用远程工具(FX)将下载好的安装包拖到linux进行解压。
- 使用tar命令解压 zookeeper-3.4.5.tar.gz
tar -zxf zookeeper-3.4.5.tar.gz
- 将解压包移动到hadoop目录下(根据自己需求)
mv zookeeper-3.4.5 /app/hadoop
- 配置环境变量
vi /etc/profile //打开环境变量配置文件

source /etc/profile //使环境变量生效
- 进入zookeeper安装目录conf目录下,复制zoo_sample.cfg并命令为zoo.cfg
cp zoo_sample.cfg zoo.cfg //复制并重命名
- 编辑zoo.cfg文件,2888:3888为固定参数不可改动
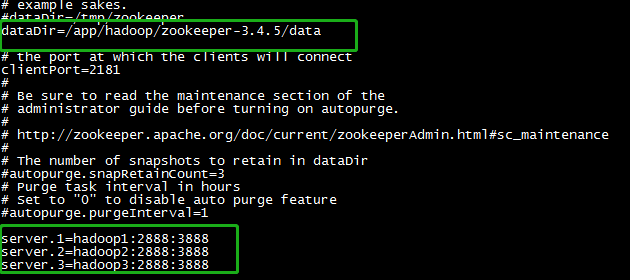
- 根据上面配置的dataDir创建data目录以及myid文件
mkdir /app/hadoop/zookeeper3.4.5/data /创建data目录touch myid //创建文件myidecho 1 > myid //将1重定向输入到myid文件,server.1 所以为1,那其他从节点为2,3
- 将刚刚配置好的这些直接发送到其他节点上,唯一改动的地方为myid(Hadoop2为2,hadoop3为3
scp -r /app/hadoop/zookeeper3.4.5 hadoop@hadoop2:/app/hadoopscp -r /app/hadoop/zookeeper3.4.5 hadoop@hadoop2:/app/hadoopscp -r /etc/profile root@hadoop2:/etc //复制环境变量文件
到此我们就将zookeeper安装完成的,接下来进入测试,先启动hadoop集群
进入zookepper bin目录下cd /app/hadoop/zookeeper3.4.5/bin 运行./zkServer.sh start 查看状态./zkServer.sh status //注意要在每个安装zookeeper节点单独启动,全部启动了才能正确显示正确显示Mode:follower查看进程 jps如有 QuorumPeerMain 则表示成功
hbase安装及配置(下载地址:http://archive.apache.org/dist/hbase/1.2.6/)
注意:根据官网提供的版本信息表,hadoop2.2.0应该安装0.96的。但是根据安装过程中遇到的各种坑,安装完成后Hmaster无法启动,或者启动后几秒钟自动消失。最后选择1.2.6版本的Hbase中与安装成功了。
- 在主节点解压Hbase1.2.6.tar.gz并移动
tar -zxf Hbase1.2.6.tar.gz mv Hbase1.2.6 /app/hadoop
- 配置环境变量
vim /etc/profile

source /etc/profile //使环境变量生效
- 进入hbase安装目录下的conf目录下编辑三个文件hbase-env.sh、hbase-site.xml、regionservers
编辑 hbase-env.sh:
export JAVA_HOME=/usr/lib/java/jdk1.7.0_80 //配置jdk路径export HBASE_MANAGES_ZK=false //设置成false,因为我们使用外部的zookeeper
编辑 hbase-site.xml:
hbase.zookeeper.quorum hadoop1,hadoop2,hadoop3 //运行zookeeper的所有节点 为奇数个hbase.zookeeper.property.dataDir /app/hadoop/hbase-1.2.6/zookeeperdata hbase.tmp.dir /app/hadoop/hbase-1.2.6/tmpdata //本地文件系统的临时文件夹hbase.rootdir hdfs://hadoop1:9000/hbase hbase.cluster.distributed true //HBase的运行模式。false是单机模式,true是分布式模式
编辑regionservers
hadoop2hadoop3
- 将配置好的hbase1.2.6发送到其他节点
scp -r /app/hadoop/hbase1.2.6 hadoop@hadoop2:/app/hadoopscp -r /app/hadoop/hbase1.2.6 hadoop@hadoop3:/app/hadoopscp -r /etc/profile root@hadoop2:/etcscp -r /etc/profile root@hadoop3:/etc //始终保持同步
- 回过头还要修改hadoop底下的core.site.xml配置件,将下面内容加入
hbase.zookeeper.quorum hadoop1:2181,hadoop2:2181,hadoop3:2181
- 同样要复制到其他节点相应位置保持一致
进入测试阶段
要记住,启动顺序为:
hadoop hdfs ===> hadoop yarn ===> zookeeper ===> hbase主节点jps

从节点jps

若Hmaster启动了,而Hregionserver无法启动或者启动之后自动消失,解决办法:同步服务器时间
[hadoop@master hbase]$ su root Password: [root@master hbase]# ntpdate pool.ntp.org [hadoop@slave1 hbase]$ su root Password: [root@slave1 hbase]# ntpdate pool.ntp.org [hadoop@slave2 hbase]$ su root Password: [root@slave2 hbase]# ntpdate pool.ntp.org